Developing on a remote server
Without Jupyter and Vim
Over the last year, I’ve been spending more and more time working on deep learning projects. All these projects call for a big GPU, of the variety that definitely doesn’t fit into my laptop. So, while I’m still sitting at my laptop writing code, I need to run the code on a machine that’s often somewhere else, such as AWS.
The most common remote development approach for deep learning is a combination of Vim and Jupyter notebooks, which is covered in many tutorials To get started I recommend Learn Vim Progressively, Vimcasts, and DataCamp’s Jupyter notebook and Notebooks on EC2 tutorials. .
However, I’ve never been happy with that workflow. My brain has never gotten used to Vim. Juypter notebooks rapidly grow to unwieldy sizes, are difficult to use with version control, and otherwise retard normal software practices. Also, I like having the features of a modern IDE available to me when developing, and while both have decent interfaces, I feel they still fall short.
This guide is the guide I wish had found 4 months ago. I assume you the reader aren’t happy with the standard recommendations. I cover the other approaches to editing code on a remote server, explain how to set them up, and weigh their comparative strengths and weaknesses. The focus is on deep learning and Python, but the majority of this advice is general enough for any other applications.
Is this for me?
No and yes.
If you’re asking “Do I need this?” the answer is probably "No". The vast majority of people are happy with Jupyter and Vim for their needs. This is guide also assumes you’re comfortable working on the command line, working with configuration files, and installing software. If you’re starting out, I’d suggest you start there and invest some time learning those tools. If you’re still unhappy with those approaches, come back here.
However, the 2 sections below on repository organization and SSH settings are applicable to any approach and will make your remote development workflow easier. I highly suggest you read those regardless of what approach
2 major approaches
I consider two basic approaches to editing code to be run on a remote server:
Edit local files and sync. In this case, there are two copies of the code, on your laptop and on the remote server. You edit the files locally and sync changes to the remote server. Rsync and PyCharm are the two options I’ll discuss here. The advantage is that you can use any editor you want, can edit code offline, and the entire codebase easily accessible. The disadvantage is you have 2 copies to keep in sync which can occasionally load to overwriting your work and the workflow can be clunky.
Edit remote files. In this case, there is one copy of the code and it lives on the remote server. Your editor needs to that machine and coordinates changes via a custom protocol. Remote VSCode and Nuclide are the two options I’ll discuss here. The advantage is that you never have to deal with conflicting files. The disadvantage is you need to be online and the instance needs to be running to do any work, and it can be challenging to navigate large codebases.
This guide is ala carte. You don’t need to do all the
Aside 1: project folder organization
Whichever route you take, making smart folder organization choices can help keep you sane. I suggest you have two top-level directories on the server: ~/projects and ~/dataThey don’t have to live in your homedir. And you can put things where ever you want on your laptop..
The projects folder contains a subfolder per project, each of which is a git repo. Keep your data outside the project folders. The less files, the faster all the approaches complete their checks for changes. Same goes for results if there’s a large amount of files being output.
Also, adopt a convention that the contents of each top-level project folder on ever get changed on either your laptop or on the remote
One such folder organization is:
~/projects
/project-1
/.git # project is a git repo
/code # [push] code files
/more-code-1
/more-code-2
/docs # [push] notes on what you're doing
/notebooks # [pull] notebooks get changed on the server
/results # [pull] results get generated on the server
/scripts # [push] scripts to run code
/project-2
...
~/data
/dataset-1
/dataset-2
...
</pre>
push folders, such as code and scripts, only get changed on the laptop and are sent to the server. pull folders, notebooks and results, only get changed on the remote server and are retrieved to your laptop.The names of the folders are unimportant. Just commit to not changing files in the same folder on both machines. Otherwise you’ll need to double- and triple-check before synchronizing changes. Just don’t do it.
Aside 2: SSH configuration
All of these methods rely on passing data through an SSH connection. Setting up your SSH configuration settings can simplify late steps.
Open the ~/.ssh/config file on your local machine. Here’s what mine looks like. Your’s will differ in specifics, but needs to follow the same basic format:
Host aws-deeplearn ec2-XXXXXX.us-west-2.compute.amazonaws.com
HostName ec2-XXXXX.us-west-2.compute.amazonaws.com # hostname again here
User ubuntu # remote server username
IdentityFile ~/.ssh/aws-key-deeplearn.pem # ssh key to use
LocalForward 9999 localhost:8888 # forward ipython notebook
The section starts with a Host line that contains both a nickname for the server and the full URL for the server. The HostName line repeats the full URL. The User line has the username to log in to the remote server. IdentifyFile points to the SSH key generated to allow logging into the server without a password. Lastly the LocalForward line redirects a port from the laptop to the server so we can view Jupyter notebooks.
I can now type ssh aws-deeplearn and log in without any extra steps. Additionally, any program that SSHs to the full hostname can log in without any extra steps. And we’ll add some additional things as we go.
Remote editing via rmate (and Visual Studio Code)
Advantages: Simple (comparatively) to setup. No syncing. Works with VS Code, Sublime, and Textmate.
Disadvantages: Can’t see entire directory structure. Need to be online and instance running.
The first approach is to remotely edit your code with the Remote VSCode extension for Visual Studio Code.
First, install and configure the Remote VSCode extension (installing Visual Code if you haven’t already). In the Visual Studio Code’s Extensions panel, search for Remote VSCode. Install it and restart Visual Studio Code.
Set the Remote VSCode section of your user settings as shown in the Usage section here. Restart VSCode again.
Next, add the following bolded line to the appropriate portion of your SSH config:
Host aws-deeplearn ec2-XXXX.us-west-2.compute.amazonaws.com
...
RemoteForward 52698 localhost:52698
Lastly, install rmate on your remote server:
$ pip install rmate
You can now type rmate <some file> in your SSH connection the remote server and the file will open in Visual Studio Code.
Syncing via rsync
Advantages: Can use any editor. Easily adaptable to your needs. Don’t need to be online.
Disadvantages: Need to run manually after making changes. Can overwrite your work. Have to like command line scripting.
Rsync is probably the most general approach to getting files to a remote server. The usage pattern is
$ rsync source_folder destination_folder
However, in practice Rsync needs a million command line arguments and if you run it from the wrong directory, you’ll either either overwrite your work or make needless copies. So we simplify with some scripts that reflect the folder organization I described above. The scripts only sync full project directories and respect our push/pull choices from above.
Copy the following 2 scripts and save them somewhere in your $PATH on your laptop and give them executable permissions:
NOTE: These scripts won’t run correctly complete their initial sync as currently written. The --exclude directives should be ignored the first time to completely sync.
You’ll also need to set an environment variable named $REMOTE_INSTANCE_URL that contains the full URL to the remote server (same as in your SSH config).
You can now run remote-push.sh and remote-pull.sh anywhere in your project and the script will intelligently sync the entire project with the copy on the remote server. The scripts also support including additional rsync options and--dry-run is a particularly handy one to check what will change before syncing.
Even with these helpers I would often get confused and try and run code on the server having forgotten to remote-push my changes first.
Syncing via PyCharm
Advantages: Lots of amazing features, including auto-sync on save. Entirely GUI-based setup. Can work offline.
Disadvantages: Costs $$$.
PyCharm is the Cadillac option. It’s a great IDE, including the free version. However, the remote sync feature is only available with the $90/year paid subscription. The full version includes syntax highlighting and code completion using the remote server’s python install, the ability to run remote scripts within the IDE, a remote debugger, and a bunch of other cool features I haven’t explored yet. Additionally, the setup is entirely within PyCharm’s GUI. It’s a quite a few steps, worth considering if you’re less comfortable with the command line.
Follow the instructions in this Medium post: Work Remotely with PyCharm Tensorflow and SSH. The section titled Setup the Console and everything after it can safely be omitted.
Remote editing via Nuclide
Advantages: Makes remote dev not feel remote. Responsive, watches remote files, notifies you of changes. No syncing.
Disadvantages: Hassle to install. Need to be online and instance running.
I recently encountered Nuclide when I started working at Facebook. It’s a package for the Atom that provides a unified development environment for Facebook’s languages. It also happens to have the best remote editor I’ve used. And it’s a pain in the ass to setup.
First, install Atom. Once installed, search for the Nuclide package and install that.
Then, install all the Nuclide server and it’s requirements. The full details are available in the Nuclide Remote Dev docs, but I’ll try and walk you through the majority of the steps here. Assuming your remote server is running Ubuntu Linux, you’ll want to run the following commandsYes, I put $s at the beginning of each line so you have to copy them
# installing prerequisites
$ sudo apt-get install -y autoconf automake build-essential libpcre3
# installing node
$ curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash -
$ sudo apt-get install -y nodejs
# installing nuclide
$ sudo npm install -g nuclide
# checking out appropriate version of watchman
$ cd ~
$ git clone https://github.com/facebook/watchman.git
$ cd watchman/
$ git checkout v4.7.0
# installing watchman
$ ./autogen.sh
$ ./configure
$ make
$ sudo make install
$ watchman --version
# configuring inotify
$ echo 999999 | sudo tee -a /proc/sys/fs/inotify/max_user_watches
$ echo 999999 | sudo tee -a /proc/sys/fs/inotify/max_queued_events
$ echo 999999 | sudo tee -a /proc/sys/fs/inotify/max_user_instances
$ watchman shutdown-server
Once that’s complete, you need to configure SSH. The Nuclide server listens on a port not exposed by default on AWS or other providers, so you need forward that port via SSH. Edit your SSH connection to include the following 2 lines:
Host aws-deeplearn ec2-XXXX.us-west-2.compute.amazonaws.com
...
LocalForward 9090 localhost:9090
LocalForward 20022 localhost:22
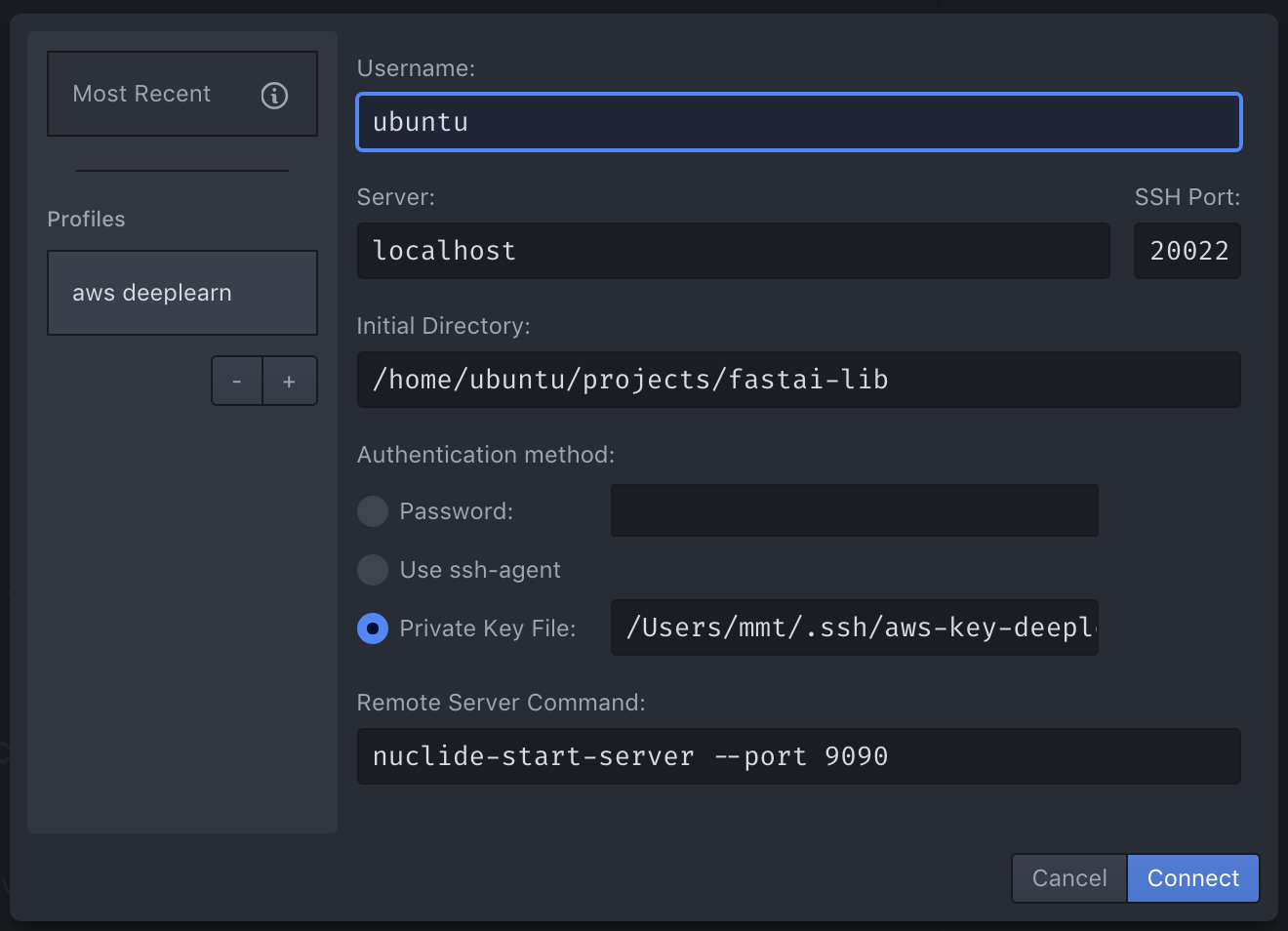 Nuclide Remote Connection dialog with appropriate settings.
Open an new SSH connection to the remote server.
Nuclide Remote Connection dialog with appropriate settings.
Open an new SSH connection to the remote server.
Lastly, you’ll need to configure the remote connection in Nuclide. Open Atom and find the connection dialog. Set it to look like the image to the right. Your Username, Initial Directory, and Private Key File will all be different.
And that should do it.
What I’m doing
So, given all this I’m sure you’re wondering what I’m using personally. I adopted the PyCharm workflow early on and have stuck with it with few complaints. I’ve started moving some of my workflow to Nuclide but haven’t fully committed. I can use both interchangably because PyCharm lets me sync on a per-file basis, and I can resolve an issues that may arise.
Not needing to deal with syncing is a big win for Nuclide, but I think the rest of PyCharm’s Python-specific remote development features may win me over.
Lastly, I must confess the title is both inflammatory and misleading. I do use Jupyter notebooks, pretty much every day. The difference is that I limit my use of them for analysing data, and examining the outputs of my work. All the intermediate steps are handled by various scripts and don’t rely on notebooks to run. It’s the best compromise I’ve found.
And some day I may yet again try to learn Vim.